Ciff:从零打造一个简化版 Dify — AI Agent 开发与运行平台
Ciff(Code It For Future)是我独立开发的一个 AI Agent 开发与运行平台,定位为简化版 Dify,面向 20-50 人小团队。支持 Agent 智能助手、知识库 RAG、工作流编排、多模型供应商适配,并提供 Web 界面和 REST API 两种交互方式。
项目从 2026 年 4 月 13 日启动,到 4 月 25 日完成全部 6 个阶段,历时约两周。后端 Java、前端 Vue 3,借助 AI 编码工具(Claude、Kimi、GLM)完成开发。本文将全面介绍项目的设计思路、技术架构和开发历程。
一、项目背景
2026 年 4 月,离职后准备找工作的间隙,我决定做一个 AI Agent 开发平台来练手。初衷很直接:
- 熟悉 AI Agent 开发流程:2026 年 Agent 应用开发已成为后端 JD 高频关键词,纸上谈兵不如动手做
- 补全技术栈:多年 Java 后端经验,但前端生疏,借此机会用 AI 辅助补齐前端短板
- 实践 VibeCoding:验证「思路清晰 + AI 执行」的协作模式能否真正提效
对比了 Dify 和 FastGPT 后,选择以 Dify 为蓝本做简化版。核心约束是:
- 不做可视化拖拽,工作流用 JSON 配置
- 只支持 API 类型工具(MCP 协议留扩展口但不实现)
- 知识库只支持 TXT 文档 + 固定长度分块
- 单机 Docker Compose 部署,不搞分布式
二、功能一览
| 功能 |
说明 |
| Agent 智能助手 |
工具调用 + 多轮对话,核心形态 |
| Chatbot 对话应用 |
基础对话,最高频入口 |
| Workflow 工作流 |
JSON 配置,线性步骤 + 条件分支 |
| 模型供应商适配 |
统一接口,OpenAI / Claude / 本地模型 |
| 知识库 RAG |
TXT 文档,固定长度分块,PGVector 向量检索 |
| 自定义工具 / API |
Agent 可调用外部 HTTP 接口 |
| Web + API 发布 |
对话界面 + REST API 双入口 |
| 认证鉴权 |
Sa-Token + JWT + GitHub OAuth |
三、技术栈
后端:JDK 17 / Spring Boot 3.3.6 / MyBatis-Plus 3.5.9 / MySQL 8.x / PostgreSQL (PGVector) / Redis 7.x (Redisson) / Resilience4j / Sa-Token + JWT / Flyway / WebClient + Reactor Netty
前端:Vue 3.5 / TypeScript / Element Plus / Vite / Markdown-it / Mermaid (流程图可视化)
基础设施:Nginx (反向代理 + SSE 透传) / Docker Compose
四、项目结构
项目采用 Maven 多模块架构,8 个子模块按业务领域拆分,依赖关系清晰:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ciff/
├── ciff-common/ # 公共模块(工具类、异常、DTO、配置)
├── ciff-provider/ # 模型供应商管理 + LLM 客户端适配
├── ciff-mcp/ # MCP 工具管理与调用
├── ciff-knowledge/ # 知识库 + RAG(文档分块、向量化、检索)
├── ciff-agent/ # Agent 管理与编排
├── ciff-workflow/ # 工作流编排与执行引擎
├── ciff-chat/ # 对话引擎(顶层编排,SSE 流式)
├── ciff-app/ # Spring Boot 启动模块(Controller / Service / Mapper)
├── ciff-web/ # Vue 3 前端应用
├── deploy/ # Docker 部署配置
├── docs/ # 架构文档与设计规范
├── rules/ # 编码规范(9 篇)
├── plan/ # 各阶段执行计划
└── 开发日记/ # 每日开发记录
|
模块依赖关系:ciff-chat 是顶层编排模块,依赖其他所有业务模块;各业务模块通过 Facade 层对外暴露接口,避免循环依赖。
五、产品展示
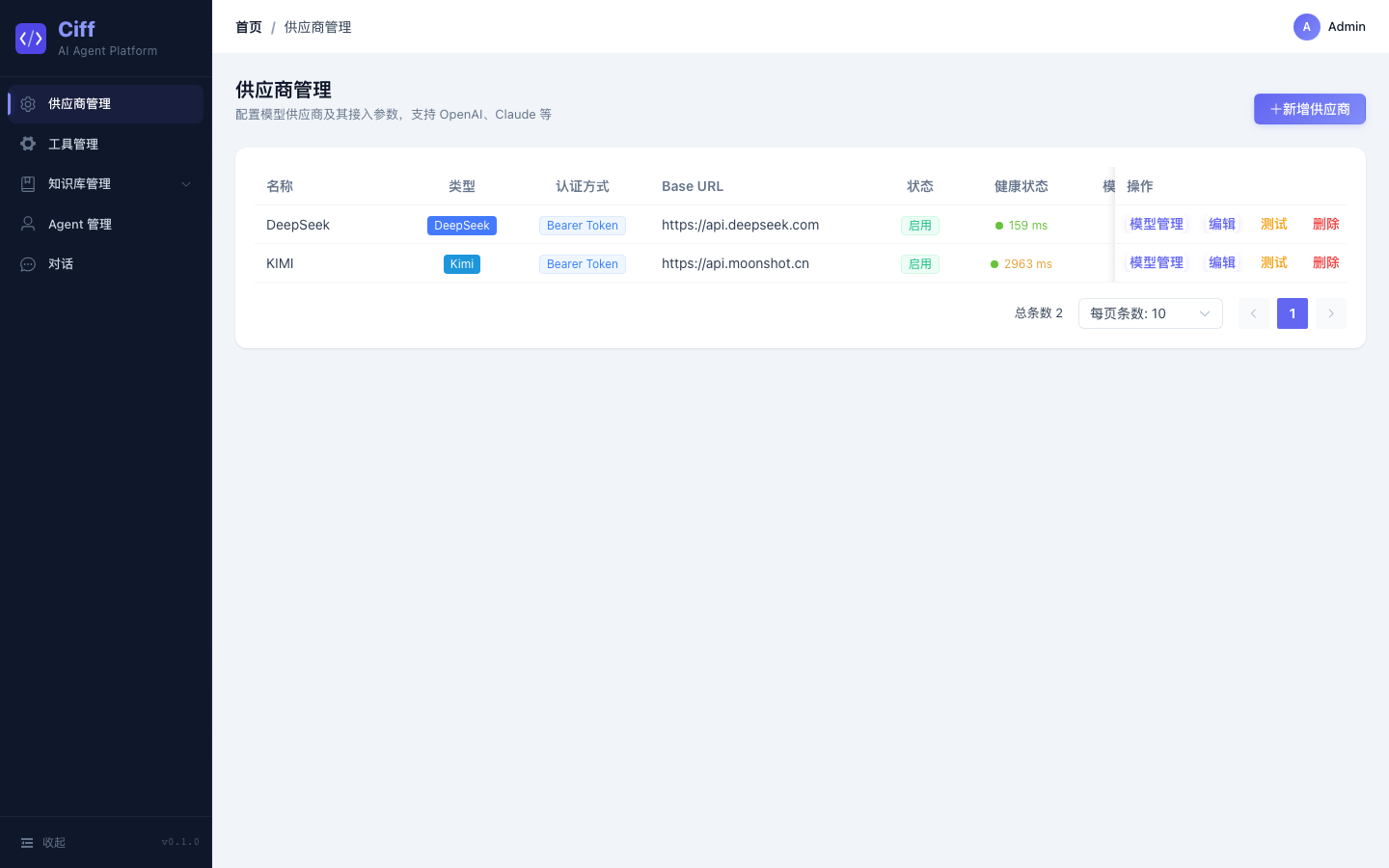
供应商与模型管理
平台支持 OpenAI、Claude、Gemini、Ollama 等多家模型供应商,统一适配层屏蔽不同 API 的差异。
![image]()
![image]()
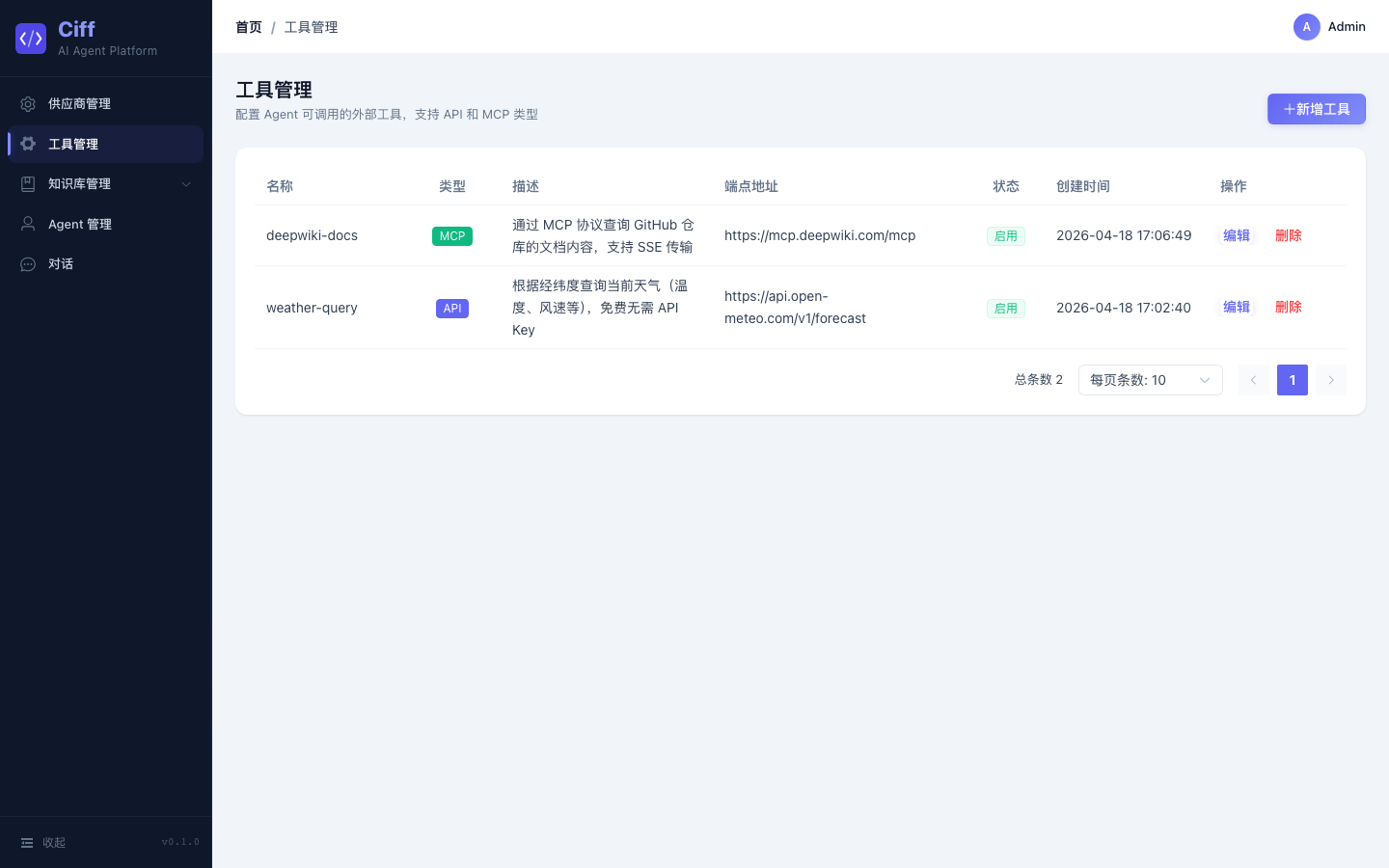
工具管理
支持 API 类型工具,通过 JSON Schema 定义入参出参,Agent 对话时可自动调用。
![image]()
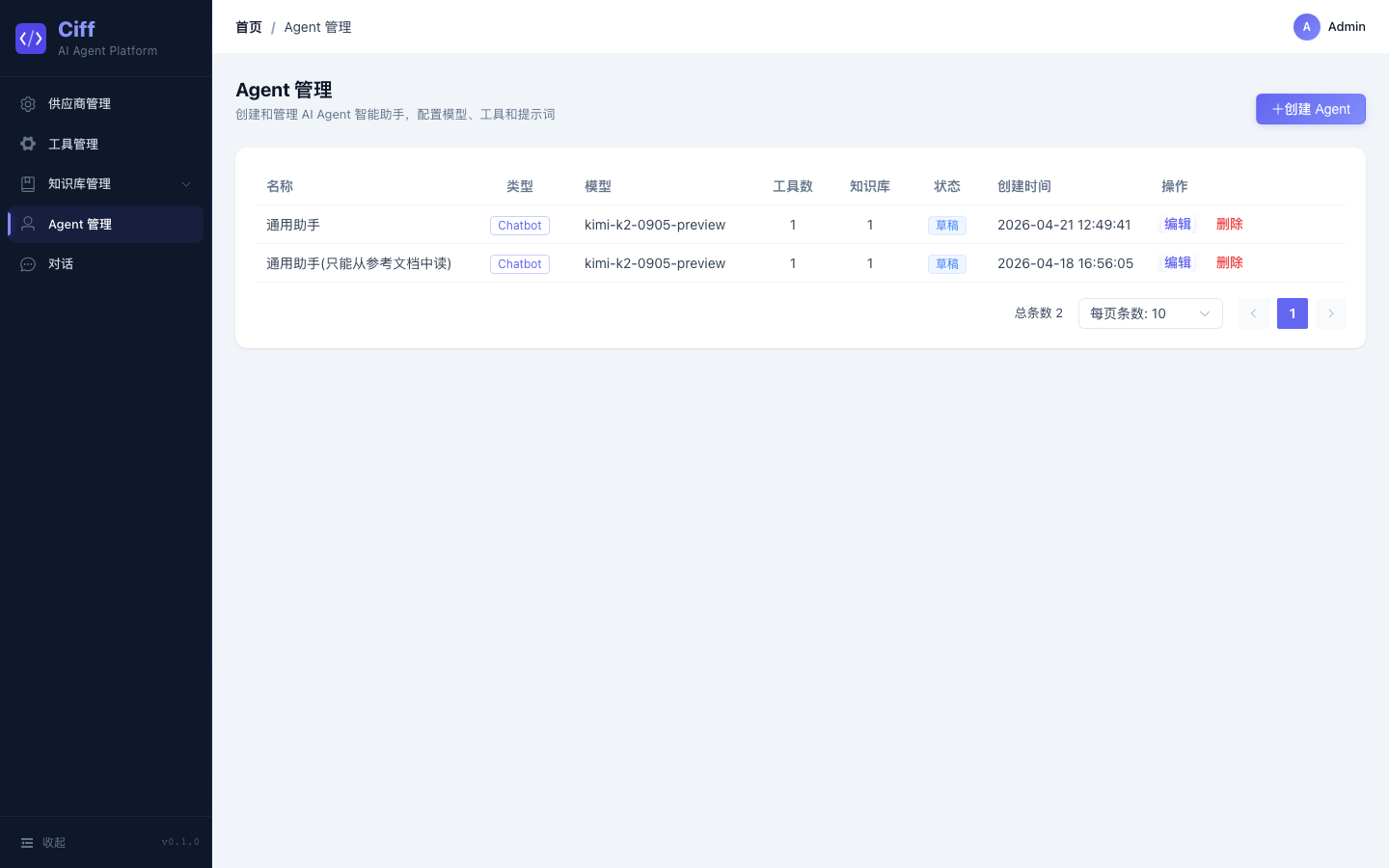
Agent 管理
Agent 是平台的核心实体,绑定模型、工具和知识库,通过 System Prompt 定义角色行为。
![image]()
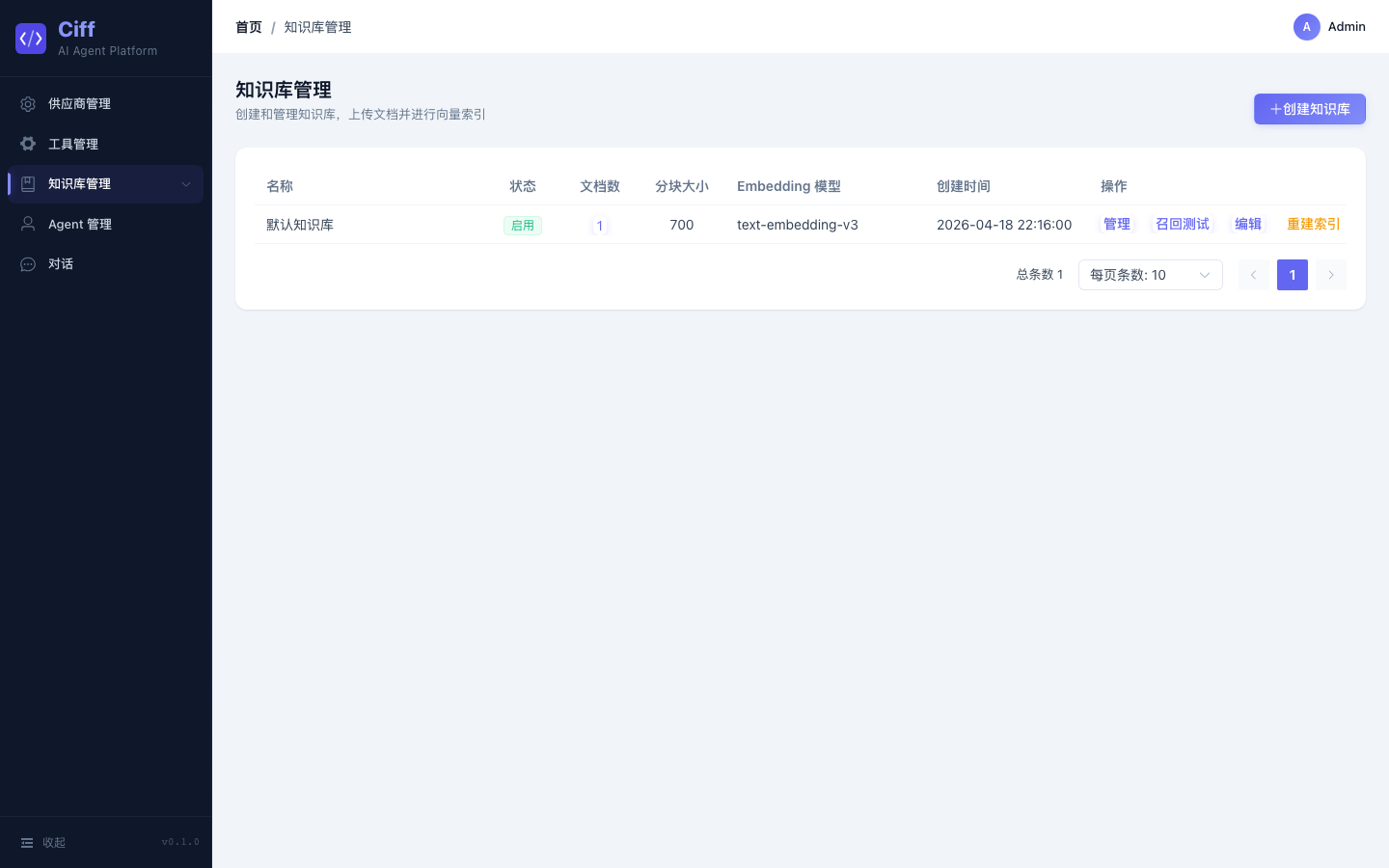
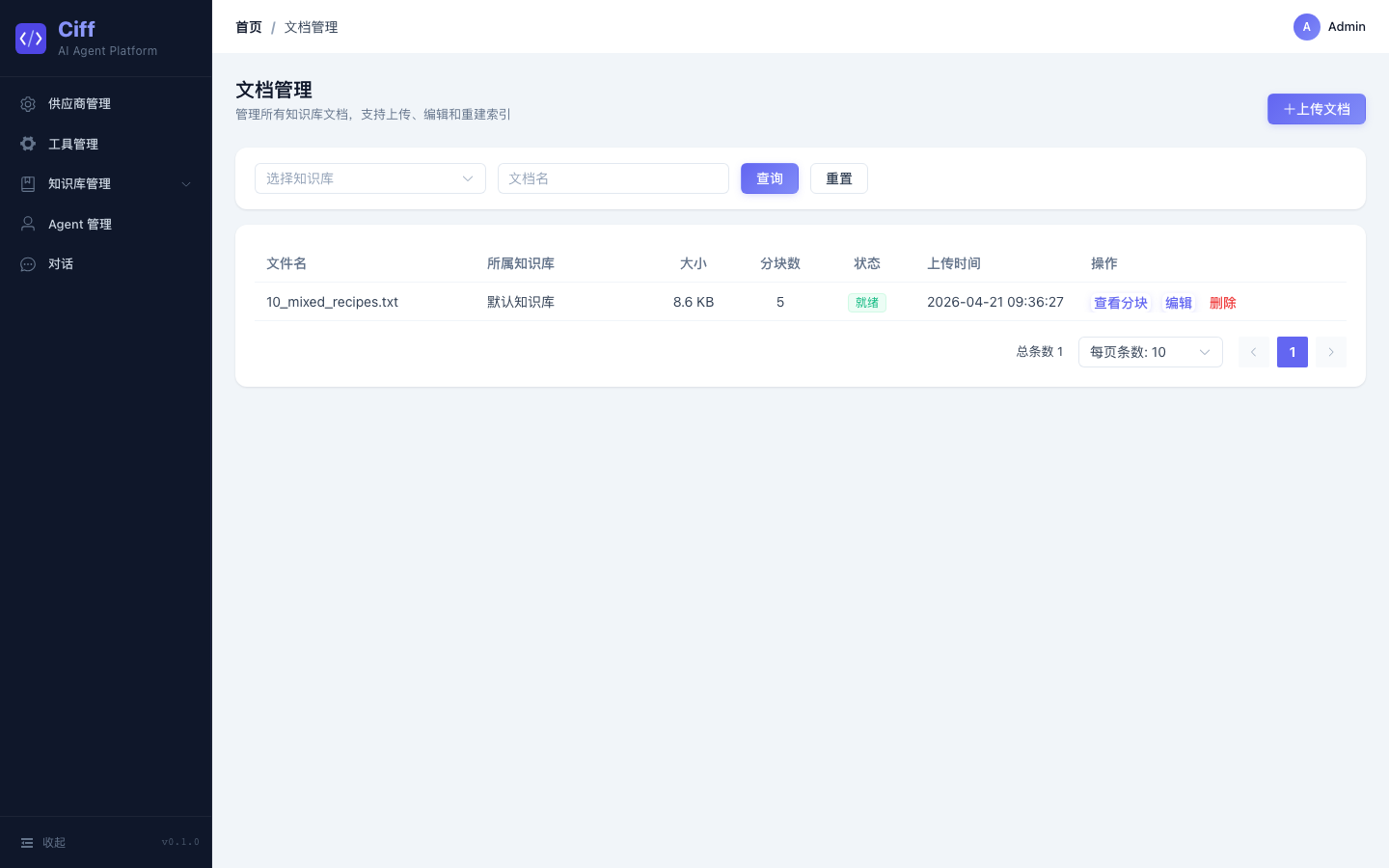
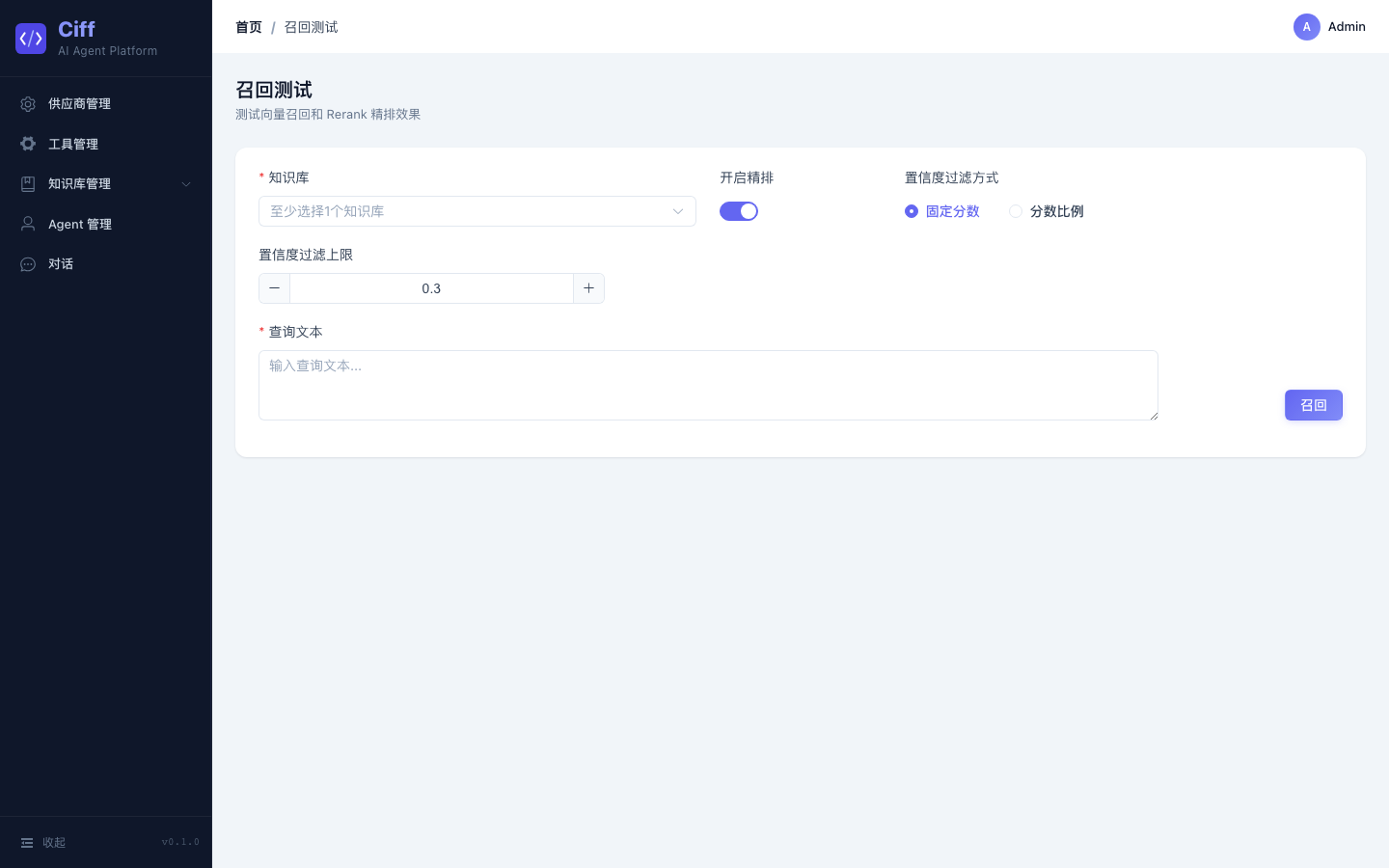
知识库与 RAG
支持上传 TXT 文档,自动分块 → 向量化 → 存入 PGVector。对话时可开启 RAG 模式,先检索知识库再生成回答。
![image]()
![image]()
![image]()
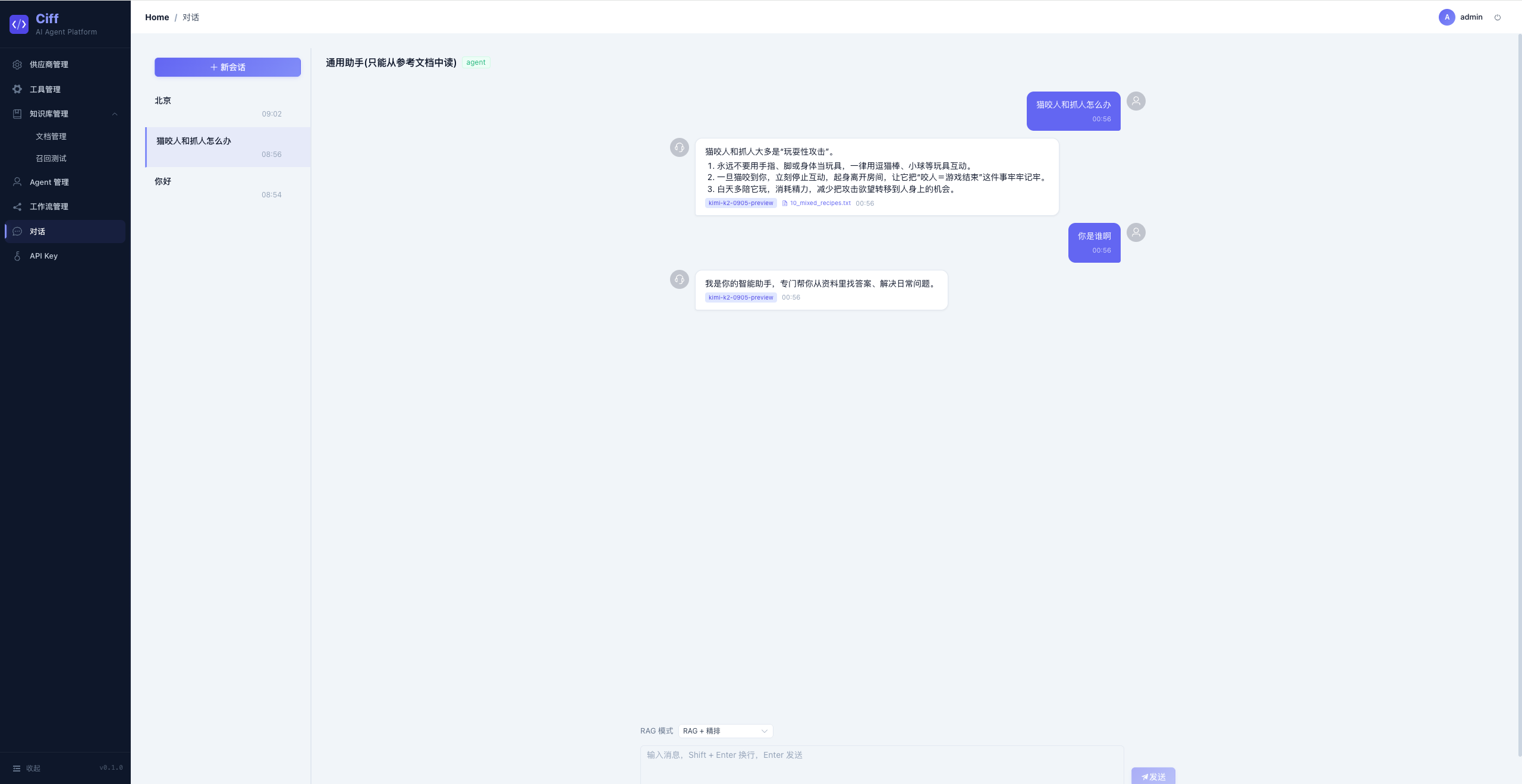
对话引擎
对话页面支持 SSE 流式输出(打字机效果)+ Markdown 渲染 + 工具调用展示。可选择不同 Agent 进行对话。
![image]()
![image]()
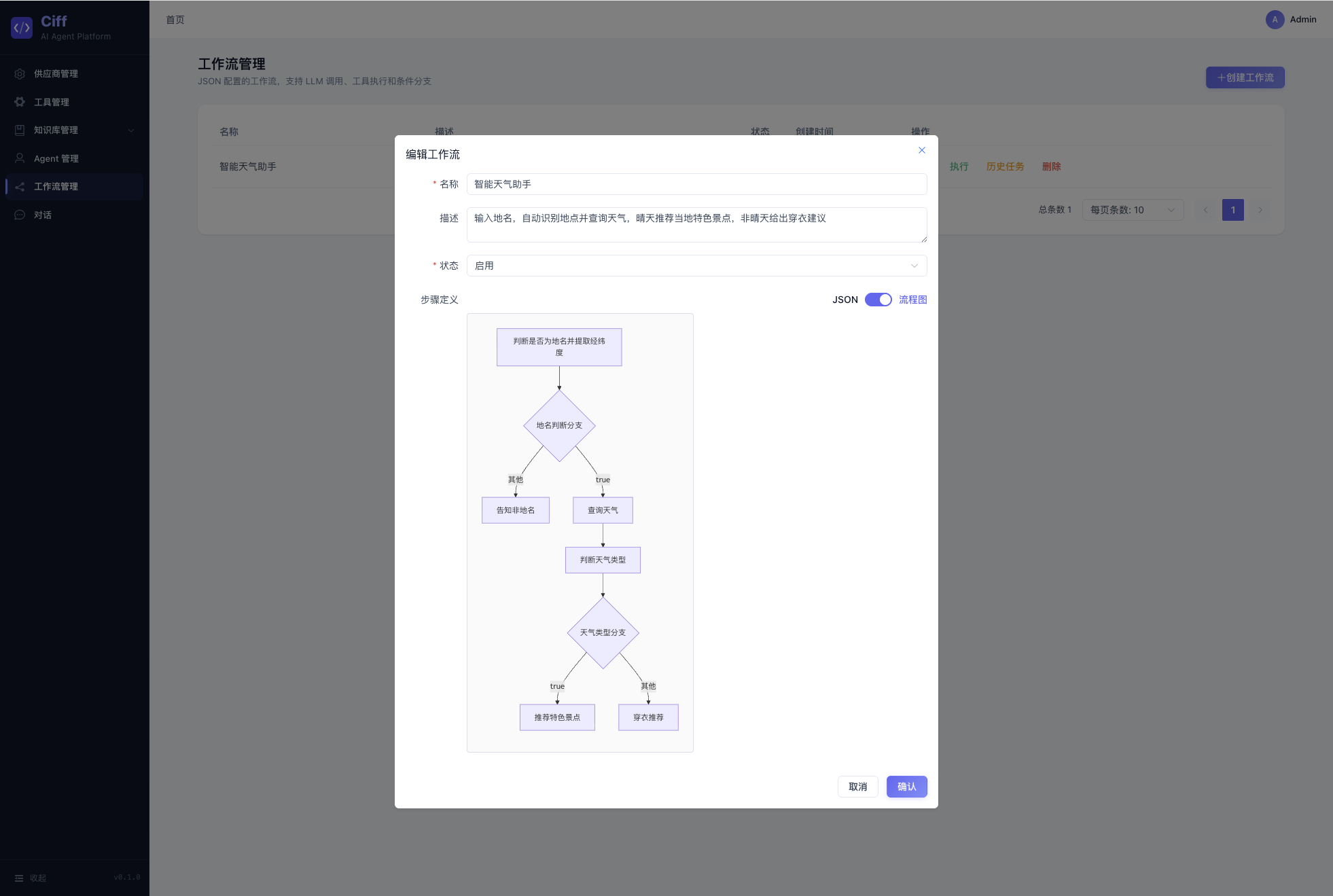
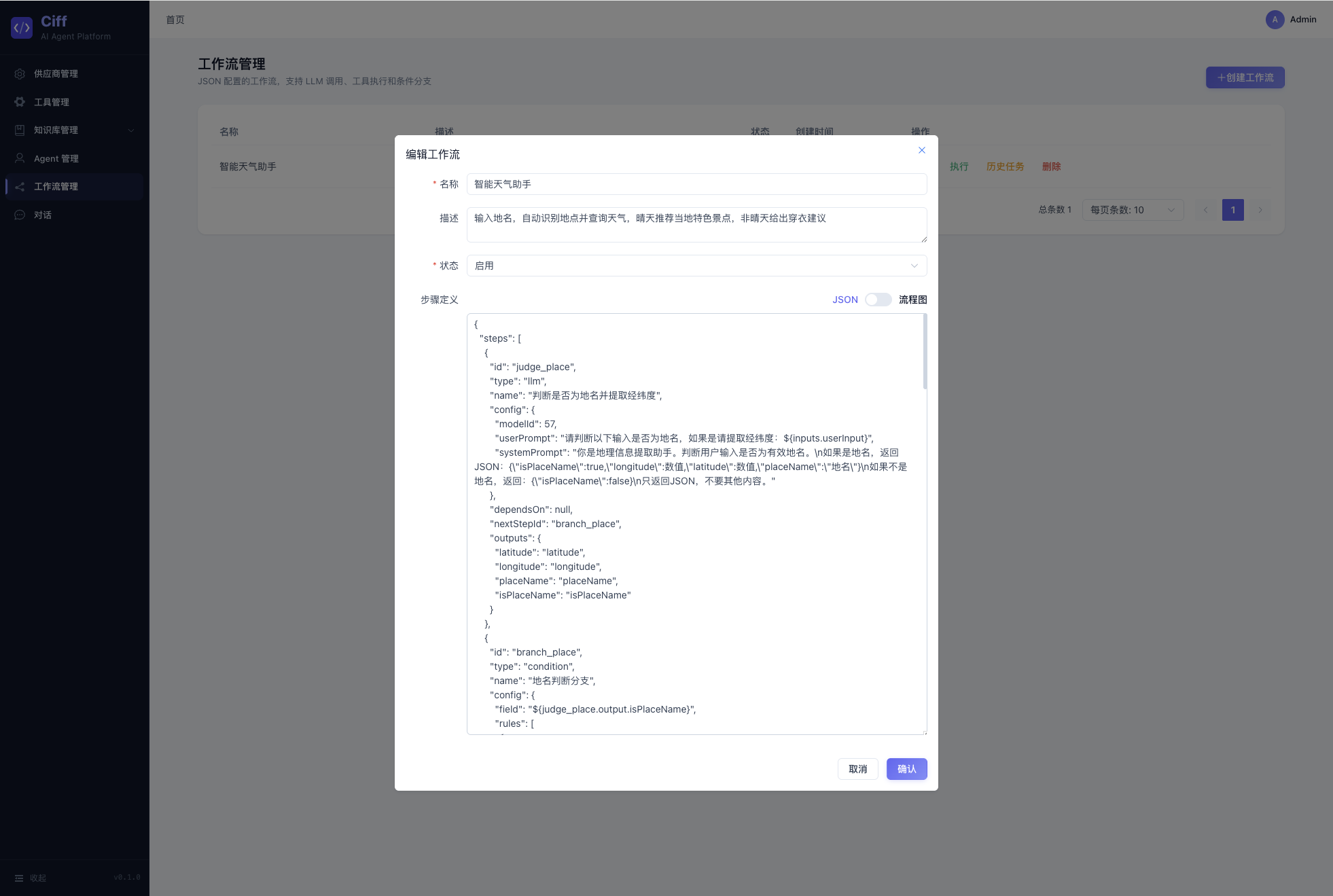
工作流引擎
工作流通过 JSON 定义,支持 llm、tool、condition、knowledge_retrieval 四种步骤类型,线性执行 + 条件分支。前端提供 JSON 编辑器和 Mermaid 流程图两种可视化方式。
![image]()
![image]()
![image]()
六、架构设计
整体架构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| ┌─────────────────────────────────────────────────────────────────┐
│ Docker Compose - Single Node │
│ │
│ ┌──────────────┐ ┌──────────────────────────────────────┐ │
│ │ Nginx │ │ ciff-server │ │
│ │ :80/443 │ │ Spring Boot 3.3 :8080 │ │
│ │ │ │ JVM -Xmx512m │ │
│ │ /api/** ────┼────►│ │ │
│ │ /sse/** ────┼────►│ ┌──────────────────────────────┐ │ │
│ │ /** ────┼──┐ │ │ Business Modules │ │ │
│ └──────────────┘ │ │ │ │ │ │
│ ▲ │ │ │ Chat Engine (SSE+Streaming) │ │ │
│ │ │ │ │ Agent (Config+Prompt) │ │ │
│ ┌────┴───────┐ │ │ │ Workflow (JSON Engine) │ │ │
│ │ ciff-web │ │ │ │ Knowledge(RAG Pipeline) │ │ │
│ │ Vue3+TS │◄──┘ │ │ MCP (Tool Execution) │ │ │
│ │ ElementPlus│ │ │ Provider (LLM Adapter) │ │ │
│ └────────────┘ │ └──────────────────────────────┘ │ │
│ │ │ │
│ │ ┌────────────┐ ┌───────────────┐ │ │
│ │ │ Resilience │ │ Thread │ │ │
│ │ │ Breaker │ │ Pools │ │ │
│ │ │ Bulkhead │ │ Tomcat: 200 │ │ │
│ │ │ Retry │ │ LLM: 10/30 │ │ │
│ │ │ Timeout(4) │ │ Biz: 5/15 │ │ │
│ │ └────────────┘ └───────────────┘ │ │
│ └──────────────┬───────────────────────┘ │
│ │ │
│ ┌─────────────┬───────────┼──────────┐ │
│ ▼ ▼ ▼ ▼ │
│ ┌──────────┐ ┌─────────┐ ┌────────┐ ┌──────────┐ │
│ │ MySQL 8 │ │Redis 7 │ │PGVector│ │ LLM APIs │ │
│ │ :3306 │ │ :6379 │ │ :5432 │ │ OpenAI/ │ │
│ │ 14 tables│ │Cache │ │1536dim │ │ Claude/ │ │
│ │ │ │Session │ │HNSW │ │ Ollama │ │
│ └──────────┘ └─────────┘ └────────┘ └──────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
|
关键设计决策
1. 四级超时策略
LLM 调用的延迟不可预测,设计了四级超时保护:
| 级别 |
超时时间 |
说明 |
| TCP 连接 |
30s |
建立 TCP 连接的超时 |
| 首个 Token |
15s |
等待模型返回第一个 token |
| Token 间隔 |
180s |
两个 token 之间的最大间隔 |
| 整体请求 |
配置化 |
单次请求的最大时长 |
2. Resilience4j 熔断保护
每个 Provider 维护独立的熔断器(Circuit Breaker)和舱壁(Bulkhead),某个模型供应商不可用时自动熔断,不影响其他供应商的调用。
3. 线程池隔离
- Tomcat 线程池(200):处理 HTTP 请求
- LLM 线程池(核心 10 / 最大 30):隔离 LLM 调用,避免慢请求占满 Tomcat
- Biz 线程池(核心 5 / 最大 15):处理异步业务(缓存刷新、文档处理等)
4. SSE 流式输出
对话接口使用 Server-Sent Events 实现流式输出,前端逐 token 渲染实现打字机效果。Nginx 配置 proxy_buffering off 确保 SSE 消息实时透传。
5. 双数据源
MySQL 存储业务数据(14 张表),PGVector 专门存储向量 embedding(1 张表)。通过 Spring Boot 多数据源配置实现读写隔离。
七、数据库设计
ER 关系图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
| ┌─────────┐ ┌──────────┐ ┌──────────┐
│ t_user │ │t_provider│ │ t_model │
│─────────│ │──────────│ │──────────│
│ id PK │ │ id PK │◄────│provider_id│
│username │ │ name │ │ name │
│password │ │ type │ │max_tokens│
│ role │ │api_base │ │default_ │
│github_id│ │api_key │ │ params │
└────┬────┘ └────┬─────┘ └────┬─────┘
│ │ │
│ ┌────┴─────┐ │
│ │t_provider│ │
│ │ _health │ │
│ │──────────│ │
│ │status │ │
│ │failures │ │
│ │latency │ │
│ └──────────┘ │
│ │
▼ ▼
┌──────────┐ ┌───────────┐ ┌──────────┐
│ t_agent │◄────│ t_agent_ │ │ t_tool │
│──────────│ │ knowledge │ │──────────│
│ id PK │ │───────────│ │ id PK │
│ user_id │ │agent_id FK│ │ name │
│ model_id │ │knowledge_ │ │ type │
│workflow_id│ │ id FK │ │ endpoint │
│ type │ └───────────┘ │param_ │
│system_ │ │ schema │
│ prompt │ ┌───────────┐ └────┬─────┘
│model_ │ │ t_agent_ │ │
│ params │ │ tool │ │
│fallback_ │ │───────────│ │
│ model_id │ │agent_id FK│◄──────┤
└──┬───┬───┘ │ tool_id FK│ │
│ │ └───────────┘ │
│ │ │
│ ▼ │
│ ┌────────────┐ │
│ │t_workflow │ │
│ │────────────│ │
│ │ id PK │ │
│ │ user_id FK │ │
│ │definition │ │ (JSON)
│ └────────────┘ │
│ │
▼ │
┌──────────────┐ │
│t_conversation│ │
│──────────────│ │
│ id PK │ │
│ user_id FK │ │
│ agent_id FK │ │
│ title │ │
└──────┬───────┘ │
│ │
▼ │
┌──────────────┐ │
│t_chat_message│ │
│──────────────│ │
│ id PK │ │
│conversation_ │ │
│ id FK │ │
│ role │ │
│ content │ │
│ token_usage │ │
│ tool_call_id │ │
└──────────────┘ │
│
┌────────────────────────────────────┤
│ Knowledge Module │
│ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ t_knowledge │ │t_knowledge_ │ │
│ │─────────────│ │ document │ │
│ │ id PK │ │─────────────│ │
│ │ user_id FK │ │ id PK │ │
│ │ chunk_size │ │knowledge_id │ │
│ │ embedding_ │ │ file_name │ │
│ │ model │ │ chunk_count │ │
│ └──────┬──────┘ │ status │ │
│ │ └──────┬──────┘ │
│ │ │ │
│ │ ┌──────┴──────┐ │
│ │ │t_knowledge_ │ │
│ │ │ chunk │ │
│ │ │ (PGVector) │ │
│ │ │─────────────│ │
│ │ │ id PK │ │
│ │ │ content │ │
│ │ │ embedding │ │
│ │ │ VECTOR(1536)│ │
│ │ │ chunk_index │ │
│ │ └─────────────┘ │
│ │ │
└─────────┼─────────────────────────┘
│
┌─────────┼─────────────────────────┐
│ ▼ │
│ ┌───────────┐ │
│ │ t_api_key │ │
│ │───────────│ │
│ │ id PK │ │
│ │ user_id FK│ │
│ │ agent_id │ │
│ │ key_hash │ (SHA256) │
│ │key_prefix │ │
│ │permissions│ │
│ │expires_at │ │
│ └───────────┘ │
└───────────────────────────────────┘
|
核心表设计说明
MySQL(14 张表):
| 表名 |
用途 |
要点 |
t_user |
用户账号 |
支持 GitHub OAuth 自动注册 |
t_provider |
模型供应商 |
API Key AES 加密存储 |
t_model |
模型配置 |
绑定供应商,含默认参数 |
t_provider_health |
供应商健康 |
连续失败次数、延迟、探活时间 |
t_tool |
工具定义 |
JSON Schema 描述入参出参 |
t_agent |
Agent 配置 |
类型(chatbot/agent/workflow)、System Prompt |
t_agent_tool |
Agent-Tool 绑定 |
中间表,多对多 |
t_agent_knowledge |
Agent-知识库绑定 |
中间表,多对多 |
t_workflow |
工作流定义 |
JSON 存储步骤和条件 |
t_knowledge |
知识库 |
分块大小、Embedding 模型配置 |
t_knowledge_document |
文档元数据 |
状态机(uploading → processing → ready/failed) |
t_conversation |
对话会话 |
绑定 Agent 和用户 |
t_chat_message |
消息记录 |
Append-only,含 token 用量和延迟 |
t_api_key |
API 密钥 |
SHA256 哈希存储,支持过期和撤销 |
PGVector(1 张表):
| 表名 |
用途 |
要点 |
t_knowledge_chunk |
向量分块 |
embedding VECTOR(1536) + HNSW 索引(余弦距离) |
数据隔离策略
- 全局资源:Provider、Model、Tool — 所有用户可见
- 用户资源:Agent、Knowledge、Workflow、Conversation、ApiKey — 用户隔离
八、开发历程
项目分为 6 个阶段(Phase 0 ~ Phase 6),通过 plan/ 目录管理每个阶段的执行计划,开发日记/ 目录记录每日进展。
Phase 0-1:基础框架 + 供应商管理(4.13 ~ 4.17)
Day 1 搭建 Maven 多模块工程骨架,完成统一响应 Result<T>、异常处理、MyBatis-Plus 配置等基础组件。Day 2 搭建前端设计系统,实现 CiffTable、CiffFormDialog 等公共组件。
Phase 1 完成供应商 CRUD、模型管理、LLM HTTP 客户端(WebClient + Reactor Netty 同步/SSE 流式)、Claude 适配器、Resilience4j 熔断保护和四级超时策略。
期间还做了 AI 编码工具对比:用 Kimi、GLM-5.1 分别做任务规划,感受两个模型在项目规划能力上的差异。
Phase 2:Agent + MCP 工具(4.17 ~ 4.18)
完成工具 CRUD(API 类型)、Agent CRUD、Agent-Tool 绑定关系、Agent 聚合控制器。关键设计是通过 Facade 层实现跨模块调用,避免循环依赖。
Phase 3:知识库 + RAG(4.17 ~ 4.19)
这是技术难度最高的阶段。核心工作:
- 双数据源配置:MySQL + PostgreSQL/PGVector,通过 Spring Boot 多数据源管理
- 文档处理流水线:上传 → 固定长度分块 → Embedding 生成 → PGVector 存储
- 向量检索:HNSW 索引 + 余弦相似度 + Top-K 检索
- Agent-知识库绑定:对话时开启 RAG 模式,先检索再生成
分块策略选了最简单的固定长度,误差控制在 10% 以内,V1 阶段够用。
Phase 4:对话引擎(4.19 ~ 4.21)
对话引擎是整个平台的顶层编排模块,串联 Agent、Provider、Knowledge、MCP:
- 非流式对话接口(测试用)
- SSE 流式对话(打字机效果)
- 工具调用(单轮)
- RAG 增强(知识检索 + 上下文注入)
- 前端 Chat 页面(会话列表、SSE 集成、Markdown 渲染)
Phase 5:工作流引擎(4.22 ~ 4.24)
工作流通过 JSON 定义,支持 4 种步骤类型:
1
2
3
4
5
6
7
8
| {
"steps": [
{ "id": "step1", "type": "llm", "modelId": 1, "prompt": "分析 ${inputs.question}" },
{ "id": "step2", "type": "tool", "toolId": 1, "params": { "query": "${step1.output.text}" } },
{ "id": "step3", "type": "condition", "condition": "${step2.output.score} > 0.8", "trueNext": "step4", "falseNext": "step5" },
{ "id": "step4", "type": "knowledge_retrieval", "knowledgeId": 1, "query": "${inputs.question}" }
]
}
|
支持变量插值 ${stepId.output.xxx}、DFS 循环检测、异步执行 + Redis 状态追踪、超时自动标记失败。前端提供 JSON 编辑器和 Mermaid 流程图双视图。
这个阶段补了 38 个单元测试,全部通过。
Phase 6:认证 + API 发布 + 部署(4.25)
最后一个阶段:
- 认证:Sa-Token + JWT 登录鉴权 + GitHub OAuth 自动注册 + Token Redis 持久化
- API Key 管理:生成 / 列表 / 撤销,SHA256 哈希存储
- 外部对话接口:
/api/v1/external/chat,API Key 认证
- Docker 部署:docker-compose + Nginx 反向代理 + SSE 透传
- 全局 UI 打磨:空状态、错误提示、响应式侧边栏
踩过的坑
Token 消耗:智谱 Coding Plan 周额度 7 天消耗 229.46M,不够用。又买了 Kimi Moderato 版(99/月),两天就耗了一半。最终结论:AI 编码是 token 密集型工作,预算要留够。
前端术语沟通:AI 对前端术语的理解有偏差。比如「label 右对齐」,AI 理解成文字右对齐而非 label 元素整体靠右。最终通过 justify-content: flex-end 解决。
序列化陷阱:外部 API 返回下划线格式(tool_calls),但生成的代码用驼峰序列化(toolCalls),导致请求失败。Jackson 的 @JsonNaming 不会级联到内部类,每个嵌套类都需要单独加注解。
Apple Silicon 兼容:Docker 镜像在 M 系列芯片上 Alpine 基础镜像平台不兼容,改用标准 Debian 镜像。
九、部署方案
Docker Compose 一键部署
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
services:
ciff-app:
build:
context: ..
dockerfile: deploy/Dockerfile
ports:
- "8080:8080"
environment:
- MYSQL_HOST=mysql
- REDIS_HOST=redis
- PGVECTOR_HOST=pgvector
- SA_TOKEN_JWT_SECRET_KEY=${SECRET}
healthcheck:
test: ["CMD", "wget", "--spider", "http://localhost:8080/actuator/health"]
interval: 30s
nginx:
image: nginx:alpine
ports:
- "80:80"
volumes:
- ./nginx/nginx.conf:/etc/nginx/conf.d/default.conf:ro
- ../ciff-web/dist:/usr/share/nginx/html:ro
depends_on:
- ciff-app
|
Nginx 关键配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
location /sse/ {
proxy_pass http://ciff-app:8080;
proxy_buffering off;
proxy_cache off;
proxy_set_header Connection '';
proxy_http_version 1.1;
chunked_transfer_encoding off;
}
location /api/ {
proxy_pass http://ciff-app:8080;
}
location / {
root /usr/share/nginx/html;
try_files $uri $uri/ /index.html;
expires 30d;
}
|
部署步骤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
cd ciff-web && npm run build
cd ciff-app && mvn clean package -DskipTests
docker network create ciff-network
cd deploy && docker-compose up -d
curl http://localhost/api/v1/health
|
十、总结
Ciff V1 从 0 到 1 跑通了 AI Agent 平台的核心链路:模型适配 → Agent 编排 → 知识库 RAG → 工作流引擎 → 对话引擎 → API 发布。
项目亮点
- 两周交付:6 个阶段,借助 AI 编码工具显著提效
- 工程规范:9 篇编码规范 + Flyway 数据库版本管理 + 完善的单元测试
- 生产就绪:熔断保护、四级超时、线程池隔离、SSE 流式输出
- 全栈实践:后端 Java + 前端 Vue 3,AI 辅助补齐前端短板
不足与展望
- 权限模块缺失,上线前需做大量功能限制
- 知识库只支持 TXT,需扩展 PDF / Word / Markdown
- 工作流是 JSON 配置而非可视化拖拽,使用门槛较高
- 未实现 MCP 协议,只支持 API 类型工具
这个项目最大的收获不是代码本身,而是验证了「清晰的架构设计 + AI 执行」这套 VibeCoding 工作流的可行性。当你能把需求拆解到足够细的粒度,AI 编码工具的输出质量会远超预期。